Why You Should Use INSERT INTO Instead of SELECT INTO in SQL
If you’ve worked with SQL long enough, you’ve likely encountered both INSERT INTO and SELECT INTO when moving or copying data between tables. Both have their purposes, but if you’re striving for maintainable, scalable, and efficient code, INSERT INTO often stands out as the better choice. Here’s why, from the perspective of a seasoned programmer
12/1/20242 min read


What’s the Difference?
SELECT INTO: Quickly creates a new table and populates it with the results of a query.
SELECT * INTO new_table FROM old_table WHERE condition;
INSERT INTO: Adds rows to an existing table from a query result.
INSERT INTO existing_table (col1, col2) SELECT col1, col2 FROM old_table WHERE condition;
Both can get the job done, but let’s dig into why INSERT INTO often comes out on top.
1. Structure Control: The Programmer’s Edge
SELECT INTO creates a table on the fly, which might seem convenient but can lead to unintended consequences:
You don’t define the schema explicitly.
Data types, constraints, indexes, and primary keys are inherited automatically (and sometimes inconsistently).
With INSERT INTO, the target table must already exist. You, the programmer, explicitly define its structure, ensuring:
Data integrity.
Schema consistency.
Compatibility with future queries.
Real-world example: Imagine a colleague running SELECT INTO to generate a table for reporting, only to find out later that the column types defaulted to something unexpected (e.g., nvarchar when they needed varchar). Debugging that is a nightmare.
AI’s take: Explicit control over schemas with INSERT INTO ensures predictable results. For relational databases, predictability is gold.
2. Constraints and Indexes: Stay Protected
Tables created with SELECT INTO don’t inherit constraints like:
Primary keys.
Foreign keys.
Unique constraints.
Indexes.
This means you risk creating a table that doesn’t enforce your data rules, leaving your database vulnerable to bad data.
Real-world example: Without constraints, you could accidentally insert duplicate rows or rows with invalid foreign keys. Good luck explaining that to your boss.
AI’s take: Constraints act as guardrails. INSERT INTO ensures you can rely on them while populating data.
3. Logs, Logs, and More Logs
SELECT INTO generates a lot of transaction logs because it’s essentially performing two tasks at once:
Creating the table schema.
Inserting the data.
This can slow down your operation significantly, especially with large datasets, as the database logs every aspect of the operation.
On the other hand, INSERT INTO separates the creation of the table from the data insertion. By defining the table upfront, you reduce the logging overhead for each operation.
Real-world example: Running a SELECT INTO on a table with millions of rows brought a database to its knees, filling up the transaction log and halting other operations. Switching to INSERT INTO prevented this issue by allowing the use of batching and predefined schemas.
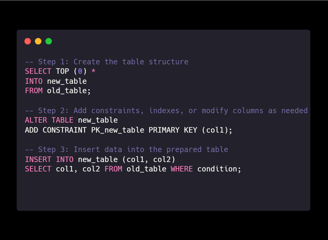
4. A Trick: Use TOP (0) for Table Creation
A great workaround for those who like the convenience of SELECT INTO but need more control is to use SELECT ... INTO with TOP (0) to create the table without any rows. This creates the structure of the table, allowing you to manually fine-tune it before inserting data.
Example: